
The Problem with Pure Cloud LLMs
Every token sent to Claude Opus or GPT-4 costs money. At scale, this becomes a serious infrastructure expense — especially when 90% of those tokens are being used for tasks that a smaller, cheaper model could handle just as well.
Most teams route everything to the frontier model because it's the path of least resistance. The result: monthly AI bills that grow linearly with usage, making certain product features economically unviable.
The Commander Architecture Solution
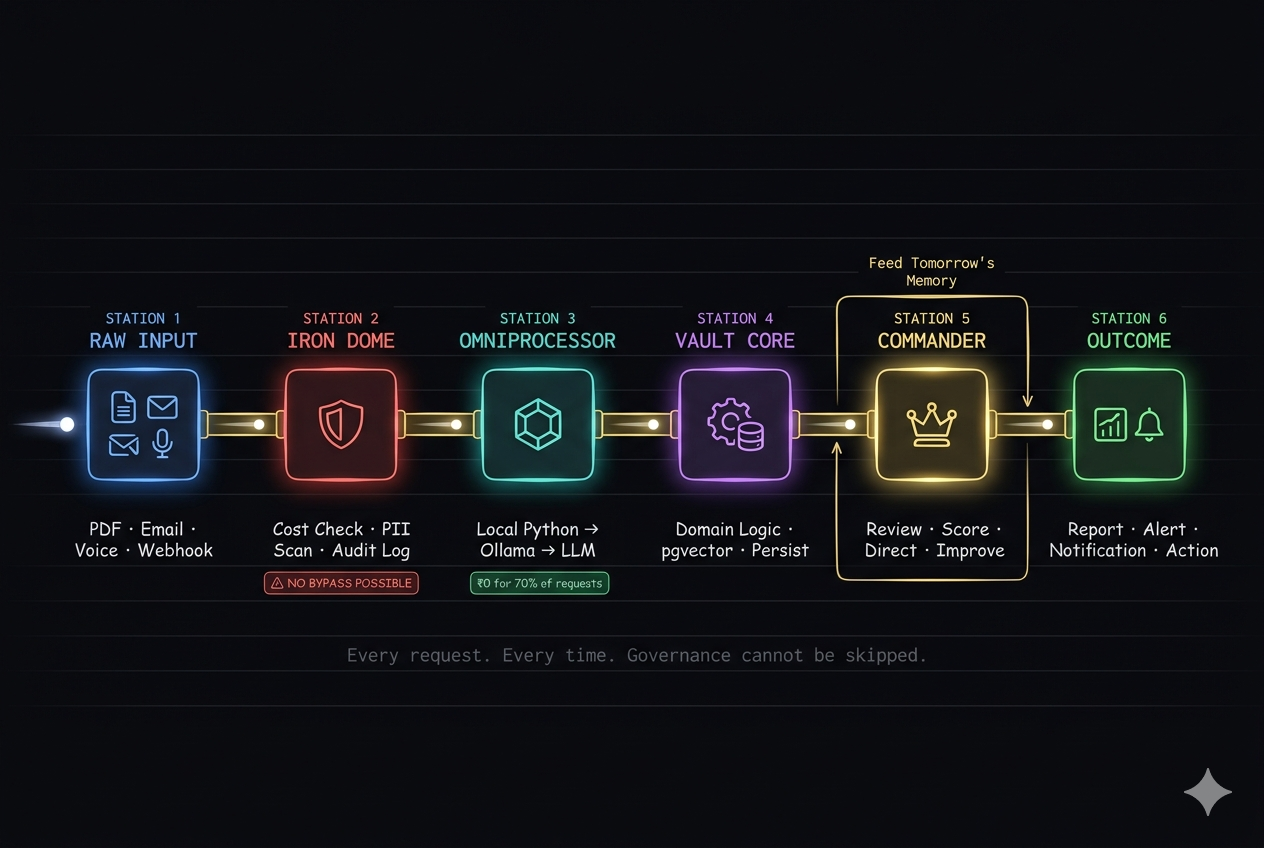
The insight behind Commander Architecture is simple: not all tasks require the same intelligence level.
- ◆Strategic decisions (content strategy, brand voice, complex reasoning) → Claude Opus
- ◆High-volume execution (script writing, classification, summarisation) → Qwen 3:32B local
- ◆Batch/media operations → Qwen 3.5:27B local
Claude acts as the Supreme Commander. It reads market intelligence, generates a directives.json file containing instructions for all downstream agents, then steps back. Qwen agents run locally via Ollama and execute at ~$0.000 marginal cost.
Prompt Caching — The Hidden 80% Saving
Even when you do call Claude, you can eliminate most of the cost via prompt caching.
System prompts are often 1,000–5,000 tokens of identical content sent on every API call. With Anthropic's prompt caching API, after the first call, cached tokens cost 90% less. At a ~90% cache hit rate, you're effectively paying 10% of the system prompt cost.
Real Numbers
| Approach | Cost per 1K tasks | Monthly (100K tasks) |
|---|---|---|
| Pure Claude Opus | ~$15.00 | ~$1,500 |
| Commander Architecture | ~$0.10 | ~$10 |
That's a 99% reduction in the extreme case — realistically 40–70% for mixed workloads where some tasks still require Claude.
Implementation: directives.json
The key artifact is directives.json — generated by Claude, consumed by all agents:
{
"session_id": "2026-06-01-morning",
"strategy": "Focus on agentic AI enterprise adoption",
"agents": {
"script_writer": {
"persona": "Senior AI solutions architect",
"tone": "authoritative but accessible",
"topics": ["Microsoft Build 2026", "MCP Protocol"],
"format": "1200-word explainer"
}
}
}Each Qwen agent reads its section of directives.json and executes accordingly. Claude doesn't need to be involved again until the next strategy cycle.
Conclusion
Commander Architecture isn't a product — it's a design pattern. The core principle: use frontier LLMs for strategy and quality control, use local models for execution volume. The savings are structural.