AI Infrastructure
& LLM Ops
We design and deploy hybrid LLM infrastructure that cuts your AI operating costs by 40–70% — through intelligent routing, prompt caching, and local inference. Not by downgrading your stack.

Most SaaS companies overpay for AI because they route everything to expensive frontier models, have no prompt caching strategy, and run zero local inference. We fix all three simultaneously using our Commander Architecture — Claude Opus as strategic orchestrator, local Qwen models as execution engines.
- →Frontier LLM costs scale linearly with volume — without routing, growth means runaway infrastructure bills
- →Prompt caching alone reduces input costs by 60–80% on repeated system prompts across agent calls
- →Local inference via Ollama eliminates per-token cost for dev, batch, and high-volume classification workloads
- →Multi-agent task delegation routes tasks to the cheapest capable model — not the most capable expensive one
Proprietary multi-agent orchestration. Claude Opus as Supreme Commander, local Qwen agents for execution. ~90% cache hit rate.
Dynamic task routing to the right model — Claude, GPT-4, Qwen local, or fine-tuned small models — based on complexity and cost.
Ollama deployment with Qwen 3:32B and 3.5:27B on your infra. Zero marginal cost for high-volume workloads.
PostgreSQL + pgVector retrieval-augmented generation. Semantic search over your business data, connected to your LLM.
Full audit and implementation of Anthropic's prompt caching API. Targeting >80% cache hit rates on system prompts.
We analyse your current AI spend and deliver a concrete roadmap showing exactly where the 40–70% reduction comes from.
Commander Architecture Setup
Visualizing the hybrid routing flow and performance tracking dashboards for our AI infrastructure implementations.
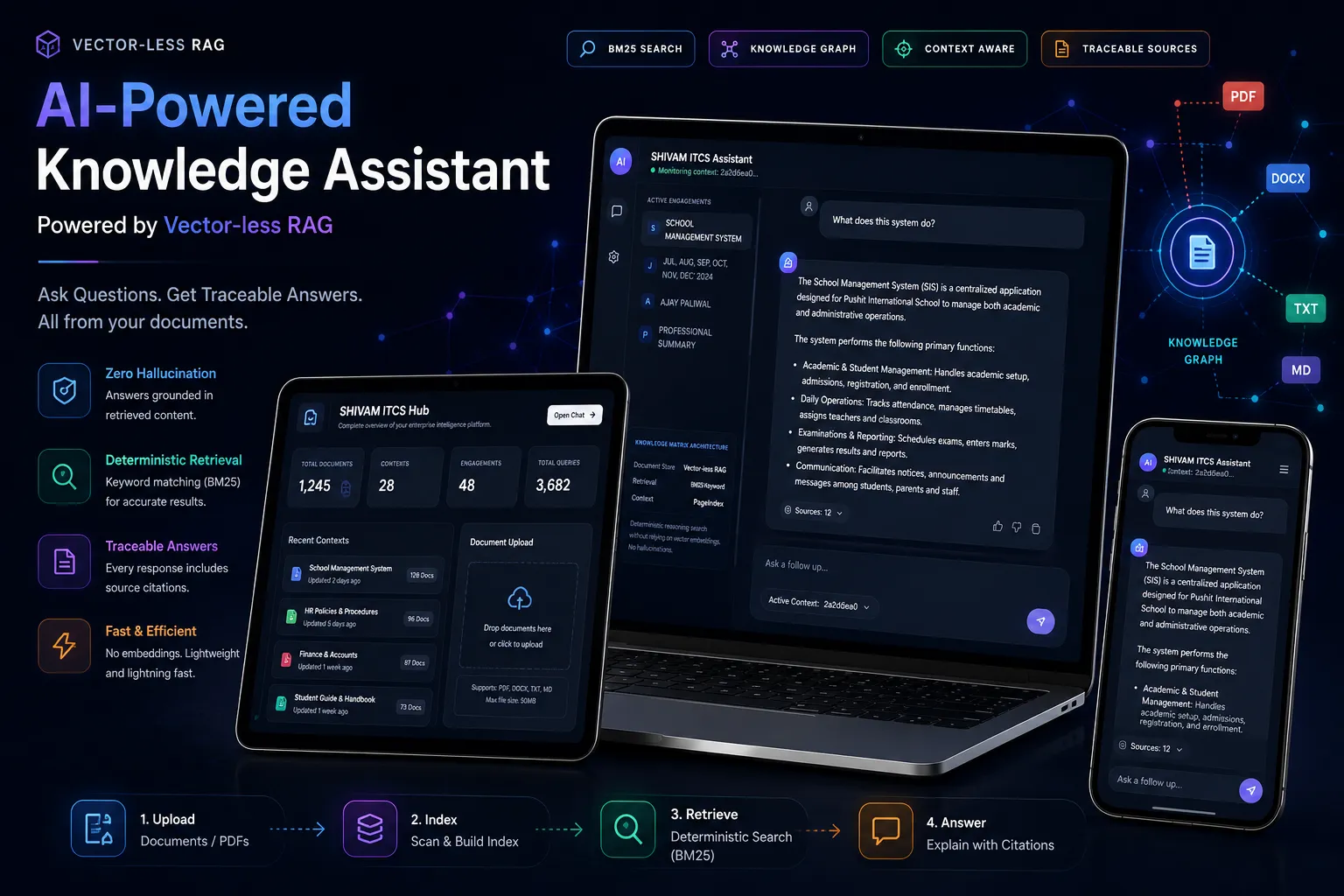
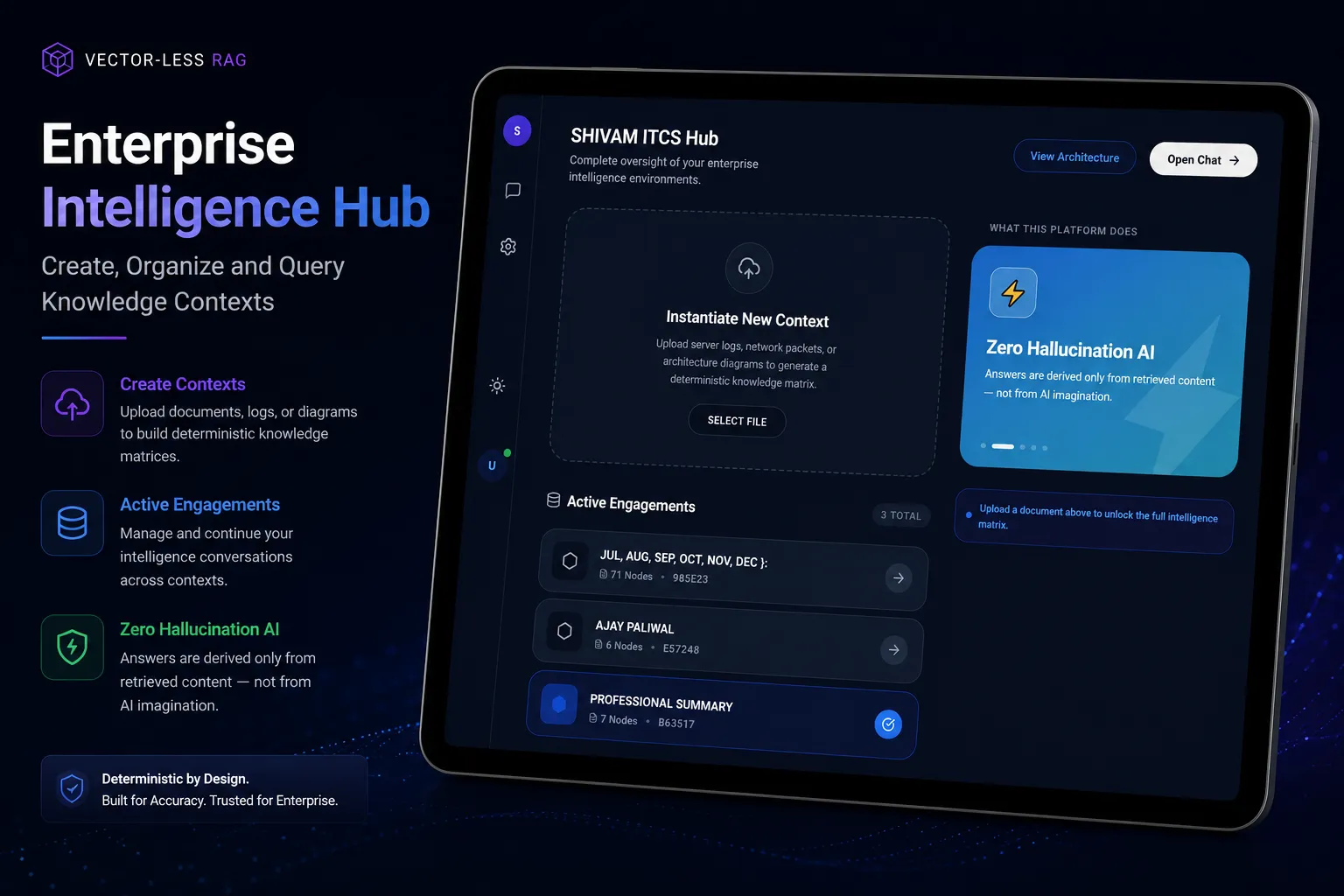
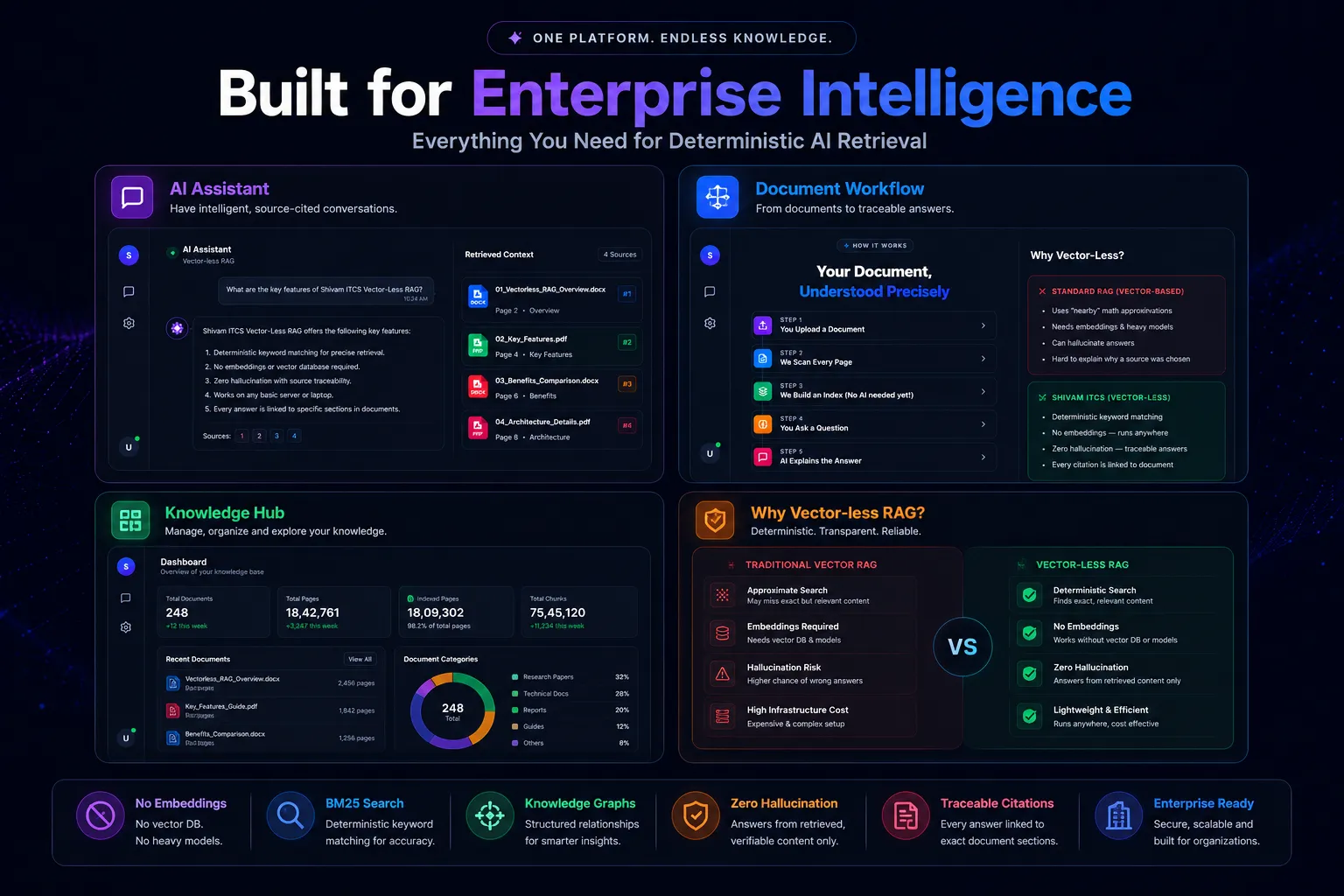


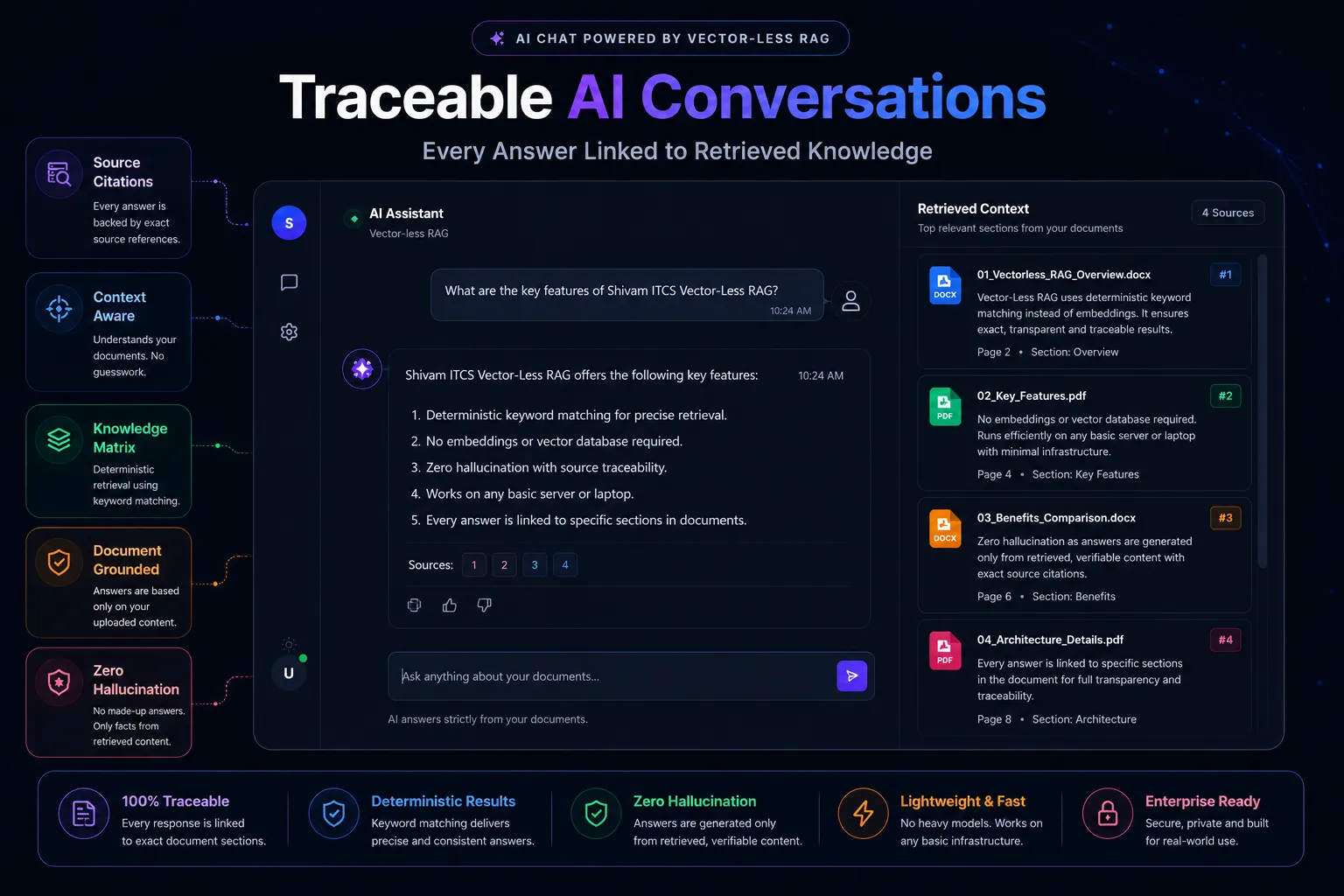

LLM Orchestration Dashboard
1 / 9
Ready to Get Started?
Tell us about your project. We'll scope it, price it, and start within a week.